반응형
Abstract
- self-attention network는 NLP 모델이지만 CV에서도 많이 활용되는 범용성이 좋은 모델이다.
- Point Transformer는 3D point cloud 처리에 self-attention을 사용한다.
- 이를 활용해서 classification, part segmentation, semantic segmentation을 수행한다.
Introduction
- point cloud는 2D 이미지의 연산 방법에 대해 즉시 적용하는 것에 대한 한계점이 있다.
- 따라서 3D 공간을 voxel화 하여 3Dcnn을 적용하거나 point cloud를 그대로 입력받고 계층적 구조를 도입한 PointNet, PointNet++모델이 연구되었고 point 간의 그래프를 형성하여 feature를 추출하는 DGCNN도 개발되었다.
- self-attention 연산자는 입력 요소들의 순서에 대해 불변하고 입력되는 크기에 대해 불변하기 때문에 point cloud 처리에 적합하다.
- 본 논문에서는 3D point cloud를 처리하기위한 self-attention layer를 개발하였고 self-attention operator의 형태나 적용, positional encoding에 의해 작동된다.
- 본 논문의 기여점은 self-attention의 데이터 처리 특성과 point cloud의 데이터 특성이 일치하기 때문에 3D 데이터를 처리하는데 적합하고 foundation 모델이 될 수 있는 가능성이 열려있으며 범용성이 높다.
Related Work
- point cloud를 처리하는 방식은 projection, voxel, point 방식으로 나눌 수 있다.
Projection-based networks
- point cloud를 이미지 평면에 투영하고 이를 2D convolution 연산을 사용해 처리한다. 하지만 이러한 방식은 point cloud의 기하학적 정보가 축소되어 feature를 추출하지 못하는 한계점을 가지고있다.
Voxel-based networks
- 3D point cloud를 균일한 voxel로 나누어 밀도가 낮은 구역은 배제하고 계산한다. 하지만 이 또한 연속적인 특성을 가진 point cloud를 강제로 이산적인 특성을 가지도록 만들기 때문에 데이터의 특성이 손실되는 한계점을 가진다.
Point-based networks
- PointNet은 non-canonical한 point cloud의 특성을 반영하여 feature를 직접 수집하였고 PointNet++는 계층적 구조를 도입하여 local feature 추출에 대한 민감도를 높였다.
- point cloud에서 point를 그래프로 연결하고 여러 접근 방식을 설정하는 모델이 있다. 가장 성능이 높은 것은 DGCNN으로서 각 point들을 그래프 컨볼루션을 수행한다.
- 연속 convolution 연산을 기반으로 하는 모델도 적용된다. 양자화 기법을 사용하지 않고 point cloud의 연속적인 특성을 보존하기 때문에 특성이 손실되지 않는다.
Transformer and self-attention
- 2D image를 처리하는 transformer는 image patch 내에서 scalar dot-product self-attention 연산을 적용하였다.
- Point Transformer는 해당 방법에서 아이디어를 제공받아 set operator에 대해 가장 적합한 point cloud를 적용함
- 기존 scalar dot-product attention과 달리 local self-attention을 적용하고 vector attention을 적용하여 각 채널별로 개별적인 가중치를 적용한다.
- 대규모 point cloud 데이터를 이해할 수 있는 기반을 마련하였으며 더 정교한 feature를 추출할 수 있다.
Point Transformer
- transformer의 일반적인 모델 공식을 리뷰하고 point cloud 처리를 위한 point transformer layer를 설명한 후 architecture를 소개한다.
Background
- self-attention operator는 scalar attention과 vector attention으로 분류할 수 있다.
- $\chi = {\mathrm{\{x_i\}}_i}$는 feature vector의 집합이라고 하고 표준 scalar dot product attention layer는 다음과 같다.
$$ y_i=\sum_{x_j\in X}\rho(\varphi(\mathrm{x}_i)^T\psi(\mathrm{x_j})+\delta)\alpha(\mathrm{x}_j) $$
- φ, ψ, α는 linear projection이나 MLP와 같은 pointwise feature transformer이다. 여기서 φ, 함수를 전치행렬로 만드는데 ψ와 dot product를 하기 위해서 만든다. 이후 position encoding을 의미하는 δ를 더해주고 소프트맥스와 같은 정규화함수 ρ를 사용해 클래스 별 확률을 계산한다. 마지막으로 α함수와 곱해주는데 이는 최종 출력되는 벡터를 계산하기 위함이다.
- vector attention layer는 attention weight 계산 방식이 다르다. attention weight는 개별 feature channel를 변조할 수 있다.
$$ \mathrm{y}i=\sum{\mathrm{x}_i\in \chi}\rho(\gamma(\beta(\varphi(\mathrm{x}_i), \psi(\mathrm{x}_j))+\delta))\odot \alpha(\mathrm{x}_j) $$
- β는 데이터의 상대적 위치를 파악하기 위한 관계함수(뺄셈)이다. 이후 각 feature에 각기 다른 weight를 적용하기 위해 γ인 MLP레이어 함수를 사용한다. 이후 position encoding 값을 더해주고 softmax함수를 적용시킨다.
- 마지막으로 hadamard product를 적용해 value vector를 곱해준다.
- Point transformer는 각 채널별로 feature가 다르기 때문에 전체의 유사도를 계산하는 것보다 각 feature에 맞게 hadamard product를 사용하는것이 알맞기 때문에 모델에서 vector attention layer를 변형시켜 사용한다.
Point Transformer Layer
- point cloud의 공간에 불규칙적으로 포함된 point set은 self-attention에 적합하다. 앞서 말한 vector attention의 수식에서 value vector에 position encoding을 더해준 값만 사용한다.
$$ \mathrm{y}i=\sum{\mathrm{x}_j\in \chi(i)}\rho(\gamma(\varphi(\mathrm{x}_i)-\psi(\mathrm{x}_j)+\delta))\odot(\alpha(\mathrm{x}_j)+\delta) $$
- 여기서 계산하는 point들은 $\chi(i)$로 표현하는데 $x_i$에서 k-nn 알고리즘을 적용한 가장 가까운 k개의 point를 대상으로 해당 attention을 진행한다.
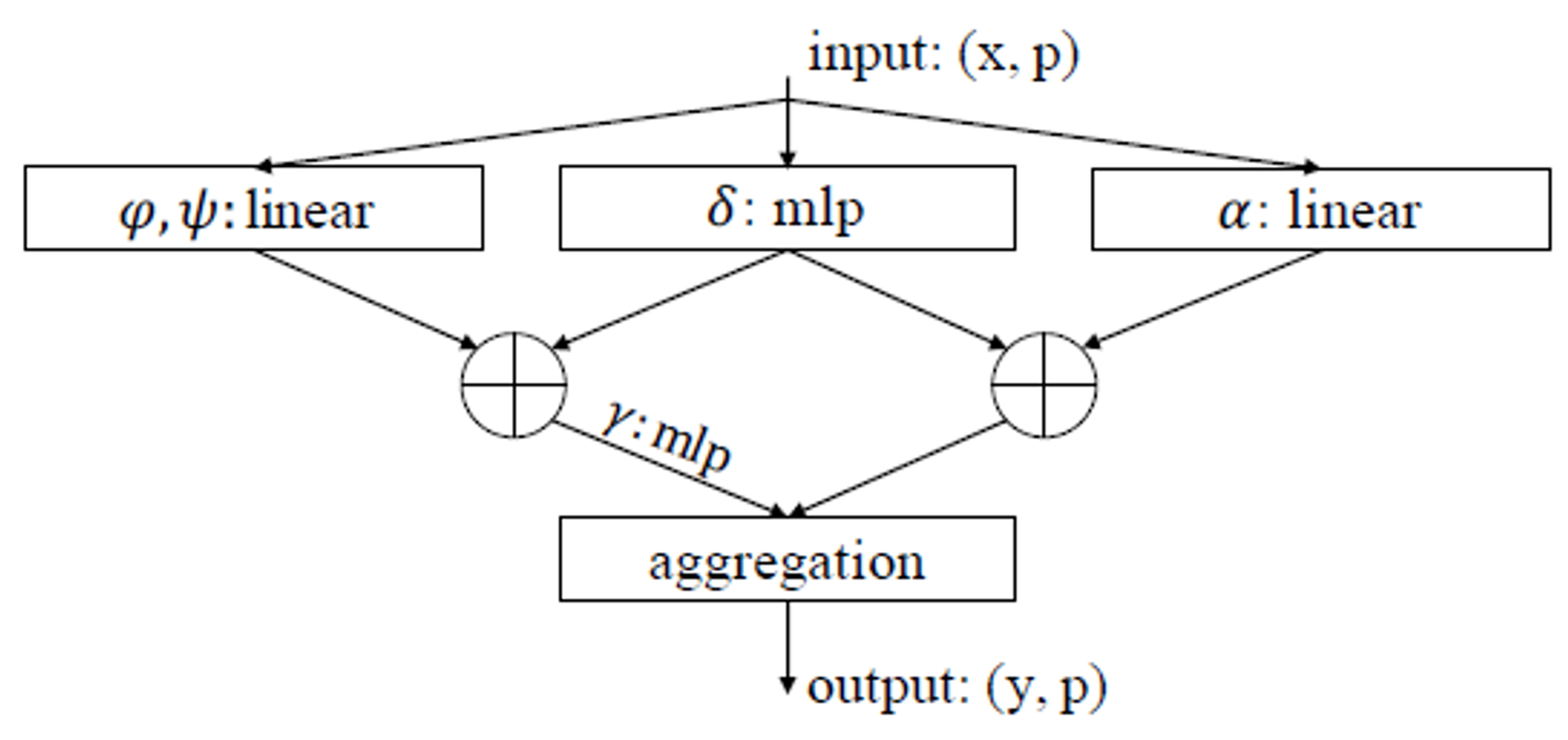
- feature를 변환하는 φ, ψ, α는 비교적 단순한 연산이기 때문에 효율적인 학습과 직접적인 관계를 학습하기 때문에 linear transform을 사용하고 δ는 point의 상대적인 위치 정보를 파악해야하기 때문에 non-linear transform인 MLP를 사용한다.
Position Encoding
- position encoding은 모델이 데이터의 local structure에 적응할 수 있도록하는 self-attention에 중요한 역할을 한다.
- sequence나 image 처리와 같은 task에서는 sin/cos와 같은 주기함수를 사용한다.
- 하지만 point cloud 처리에서는 point의 좌표가 position encoding의 후보가 된다.
$$ \delta=\theta(\mathrm{p}_i-\mathrm{p}_j) $$
- θ는 두 개의 linear layer와 ReLU 함수를 포함하는 MLP이다.
- $\mathrm{p}_i, \mathrm{p}_j$는 각 point의 좌표이다.
- position encoding은 기존 vector attention과 다르게 attention branch와 feature transformation branch 모두 사용된다. 학습 가능한 position encoding이 가장 큰 특징이다.
Point Transformer Block
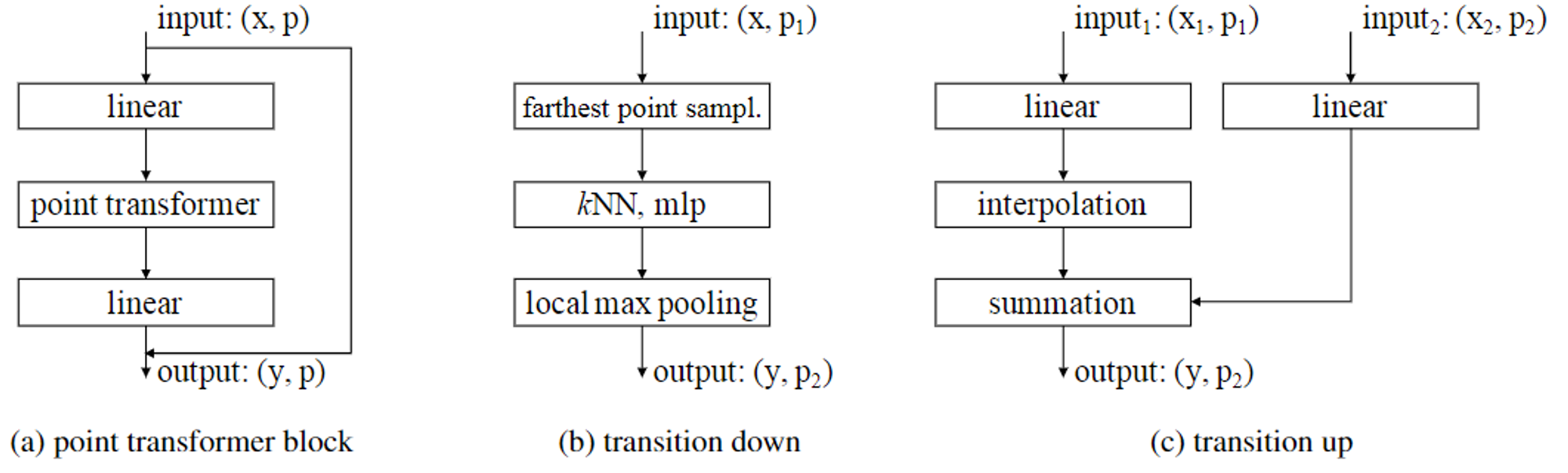
- 다음과 같이 point transformer 블록을 중심으로하는 point transformer block를 구성한다. 해당 블록에는 self-attention layer, linear projection, residual connection이 포함되어 있다.
- point transformer block 단계에서는 feature를 추출하는 단계로서 point transformer 단계 사이에 있는 linear 단계는 residual connection을 더 쉽게 구성할 수 있도록 한다.
- point transformer 단계 전 linear 단계는 input feature를 변환하여 point transformer이 더욱 feature 추출을 유용하게 사용할 수 있도록 한다.
- point transformer 단계 후 linear 단계는 추출된 feature의 표현을 극대화하기 위해 linear transform을 진행한다.
Network Architecture
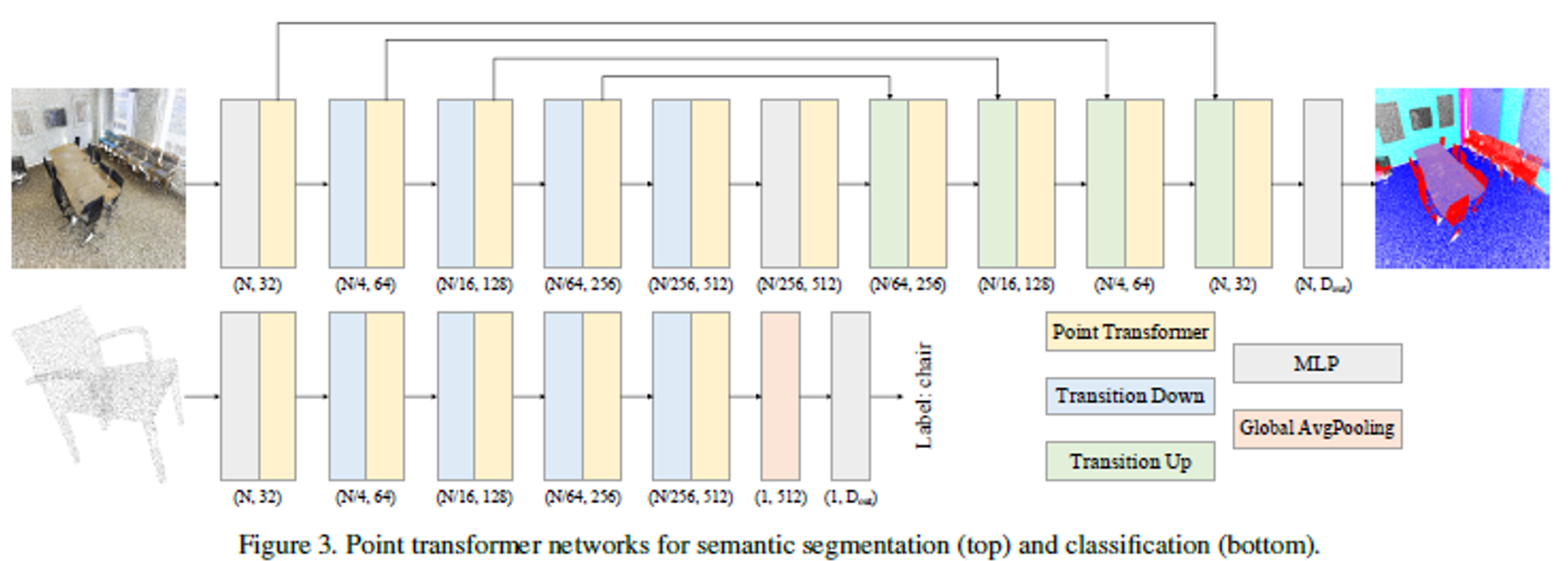
- network 구조는 convolution 연산을 사용하지 않으며 point transformer layer, transform, pooling에 기반한다.
- backbone structure
- segmentation과 classification을 위한 network architecture는 5단계의 down sampling 구조로 되어있다.
- 각 단계의 down sampling rate는 [1, 4, 4, 4, 4, 4]이기 때문에 각 단계의 cardinality는 [N, N/4, N/16, N/64, N/256]으로 2^2만큼 줄어든다.
- 더 빠른 처리를 위해 경량화된 backbone를 구성할 수도 있다.
- 연속된 모델들은 feature encoding 또는 decoding을 위한 transition up/down 단계와 결합되고 residual connection을 transition up 단계에 연결한다.
- Transition down
- 해당 단계의 핵심 기능은 point cloud의 feature를 잘 포착하기 위해 cardinality를 감소시키는 것 이다.
- 입력 point set을 $\mathcal{P}_1$, 출력 point set을 $\mathcal{P}_2$라 한다.
- $\mathcal{P}_1$에서 가장 먼 지점인 point에 FPS 알고리즘을 사용하고 해당 지점에서 knn 그래프를 사용해서 $\mathcal{P}_2$를 추출한다.
- 해당 구역에서 가장 높은 가지는 local max pooling을 진행하여 효과적인 point set을 구축한다.
- Transition up
- segmentation을 하기 위해서는 cardinality를 다시 증가시켜야 한다. ⇒ U-Net 구조 채택
- down sampling된 $\mathcal{P}_2$를 다시 $\mathcal{P}_1$에 mapping하는 방식으로 진행한다.
- 각 입력 point feature를 linear transform하고 보간법을 통해 $\mathcal{P}_1$에 mapping한다. skip connection을 통해 제공되는 해당 인코더의 feature와 결합되어 요약된다.
- output head
- segmentation의 최종 단계에서는 input point set의 각 point에 대한 feature vector를 생성한다. 이후 MLP layer를 통과하며 최종 logit에 mapping한다.
- classification의 최종단계에서는 point feature에 대해 global average pooling을 적용하여 feature vector을 얻고 MLP layer를 통과하며 classification logit을 얻는다.
Experiment
- 실험은 semantic segmentation을 위해 S3DIS를 사용하고 classification을 위해 ModelNet40, part segmentation을 위해 ShapeNetPart를 사용한다.
Semantic Segmentation
- Area 5를 test에 사용하거나 6-fold cross vaildation을 사용해 평가하였다.
- 평가지표는 mIoU, mAcc, OA(전체 point별 정확도)
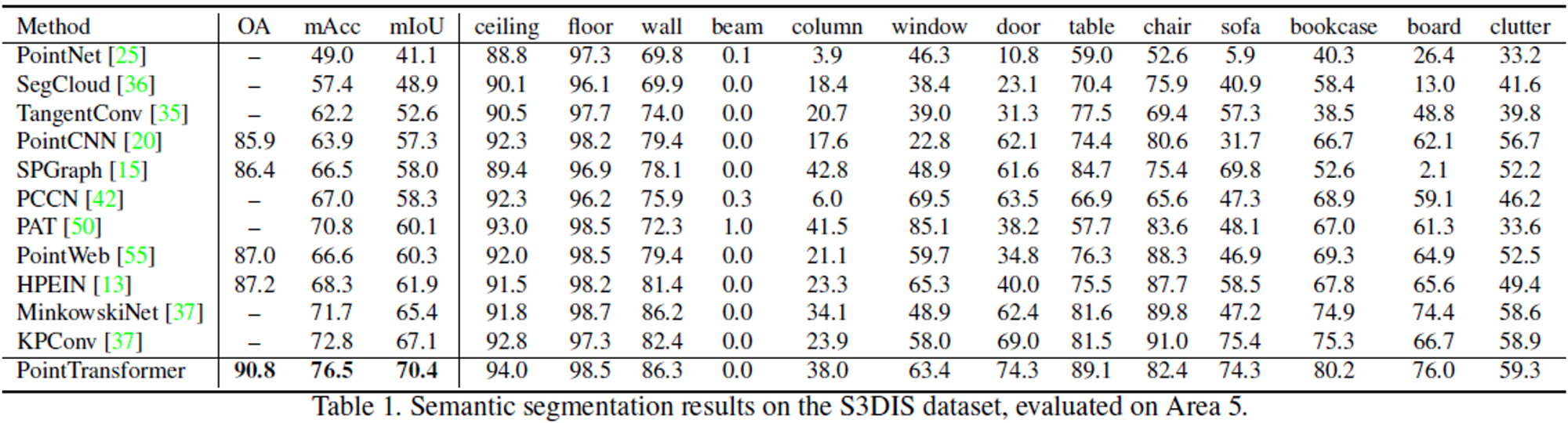
- Area 5로 평가하였을 때 모든 평가지표에서 point transformer이 가장 높고 성능이 비슷한 모델인 KPConv, SparseConv보다 파라미터 개수가 적다.
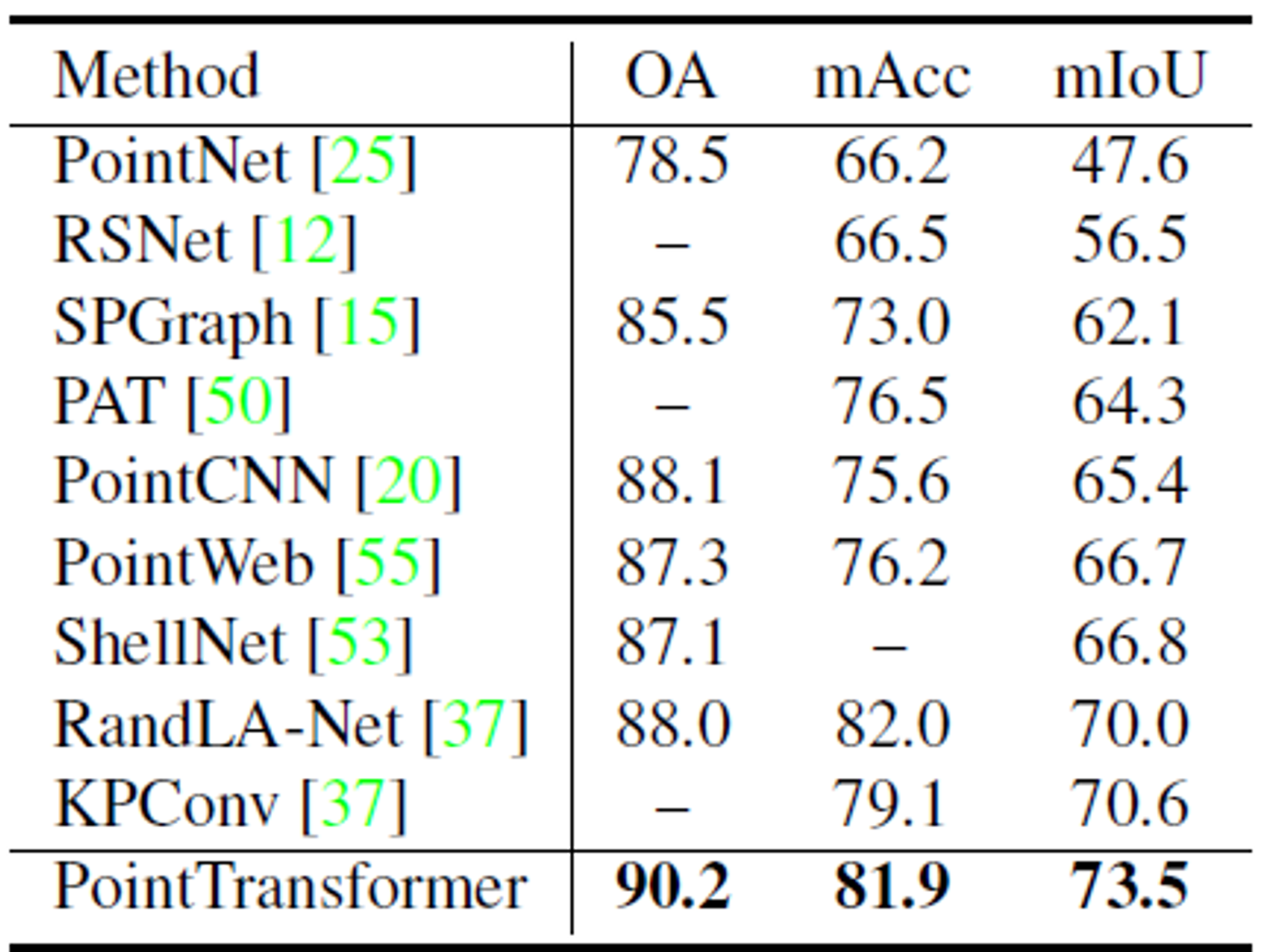
- 6-fold cross validation을 사용한 평가지표도 모든 성능지표에서 가장 높은 성능을 기록하였다.
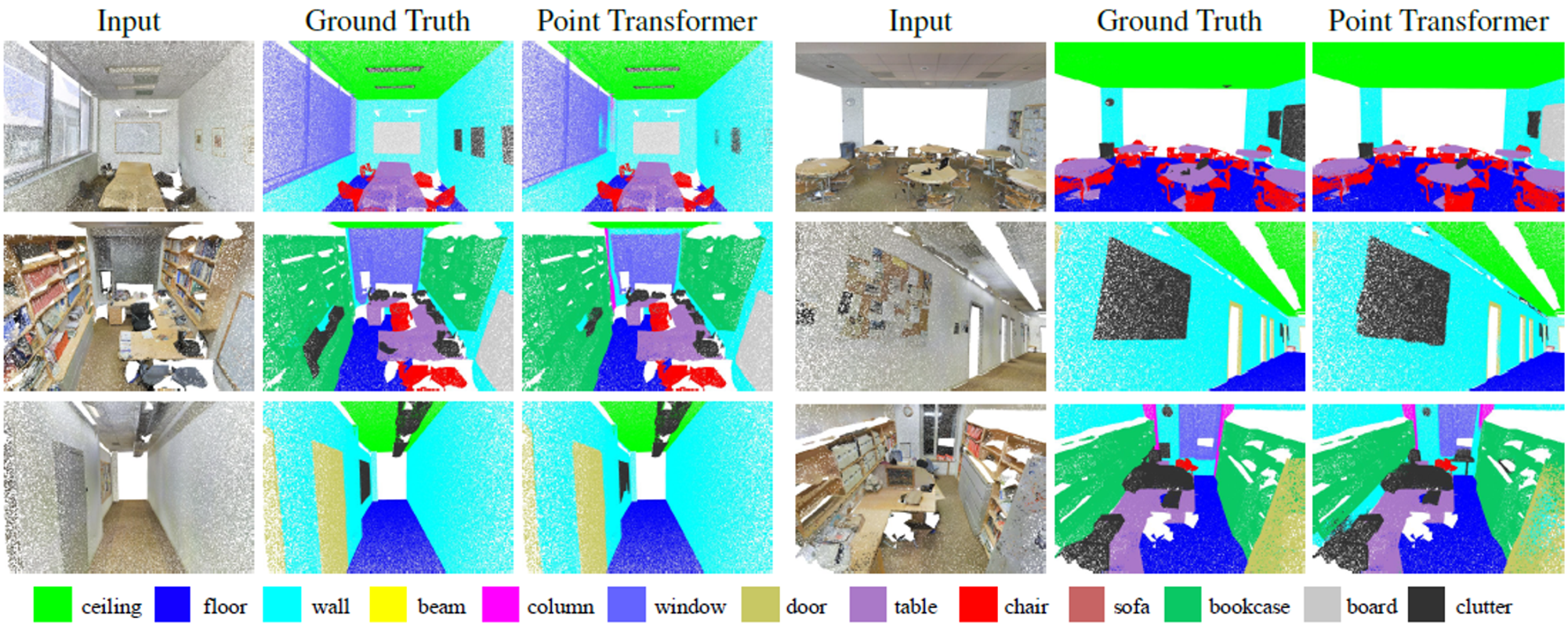
- 정답과 유사한 시각화 결과를 보여준다.
Shape Classification
- 분류를 위한 평가지표로는 mAcc와 OA를 사용한다.

- voxel, image 방식을 사용하는 모델과 point를 그대로 받아서 사용하는 모델보다 항상 더 높은 성능을 기록하였다.
- attention 기반 모델인 Point2Sequence나 point 기반 모델인 KPConv, 그래프 기반 모델인 DGCNN보다 분류 성능이 매우 뛰어나다.

Object Part Segmentatioin
- 평가지표로 cat.mIoU, ins.mIoU를 사용한다.
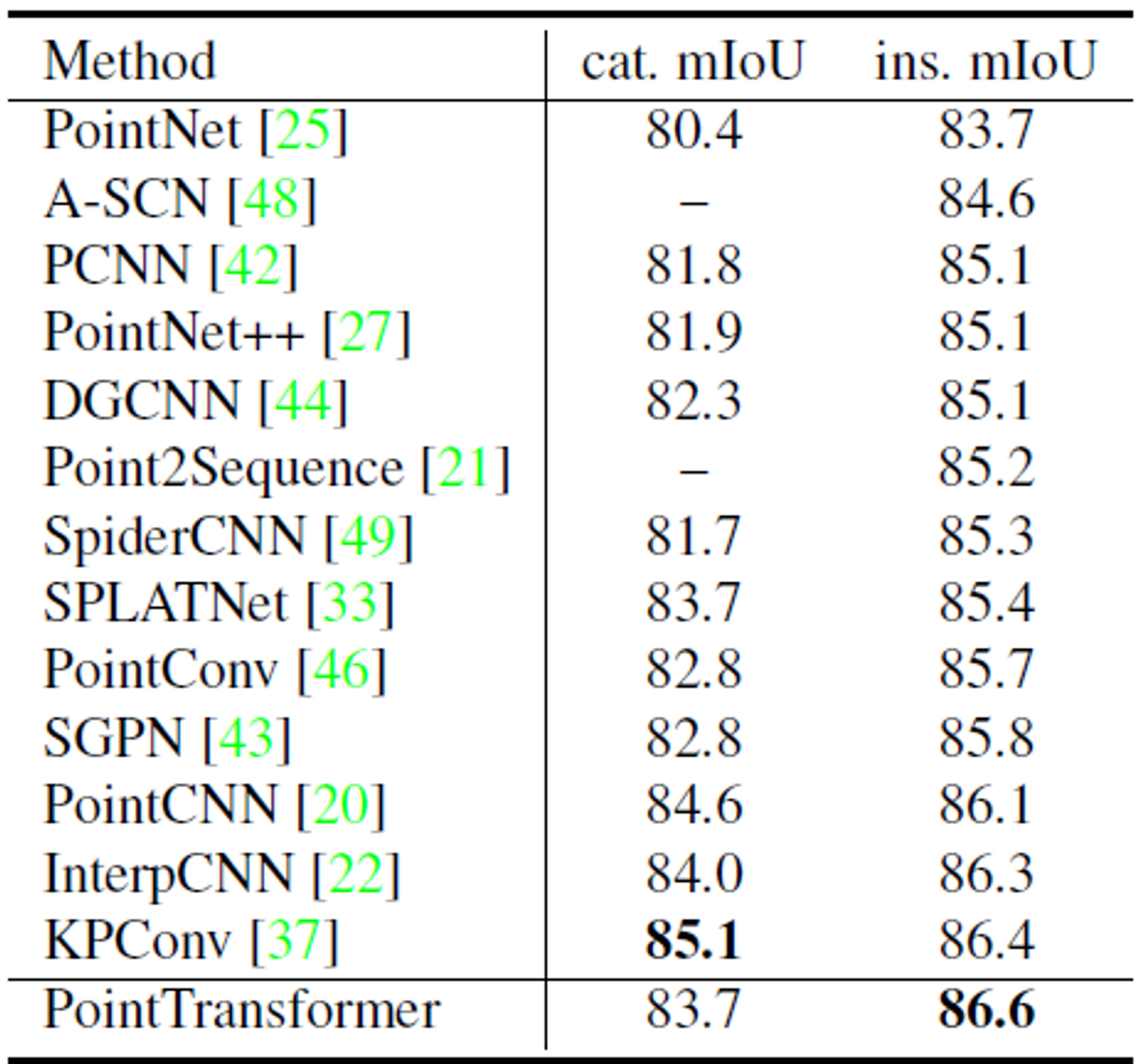
- ins.mIoU는 가장 높은 성능을 기록했지만 cat.mIoU는 convolution연산을 사용하는 모델에 뒤쳐진다.
- 훈련을 진행할 때 loss-balancing을 사용하지 않아서 성능이 낮다.
- loss-balancing은 특정 카테고리를 더 잘 맞추기 위해서 loss function의 가중치를 조정하는 것이다.

Ablation Study
- Number of neighbors
- knn 알고리즘의 k값에 대한 성능평가이다.
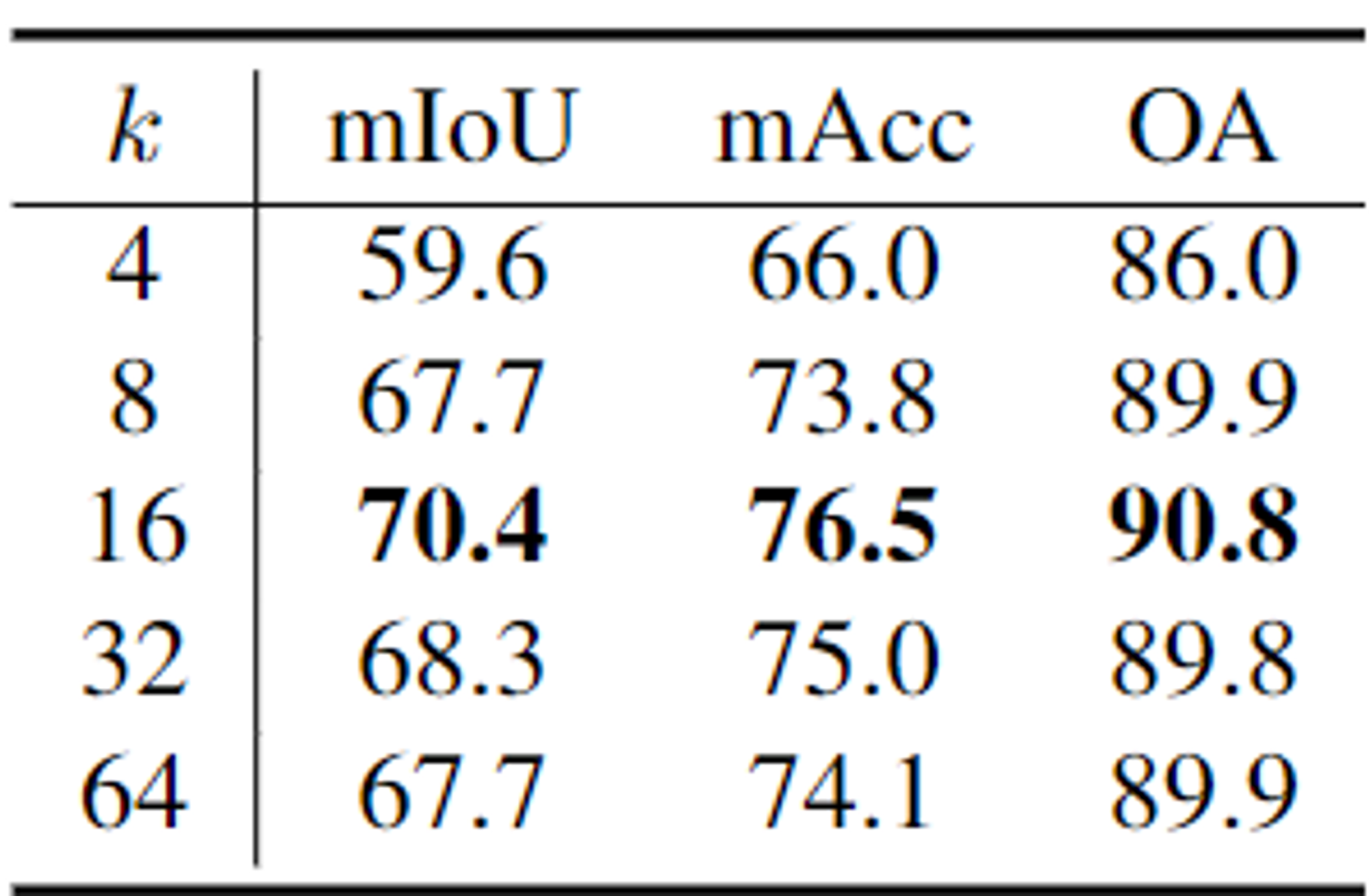
- k값이 작으면 모델이 예측을 위한 충분한 point를 학습하지 못하고 k값이 크면 멀고 관련성이 떨어지는 point에 대해 noise로 인식하여 모델의 정확도가 낮아진다.
- Softmax regularization
- ρ를 제거하고 Area 5에 대한 연구를 수행하였을 때 성능이 전체적으로 낮아졌다. 이는 정규화함수에 대한 필요성을 시사한다.
- Position encoding
- position encoding를 사용하지 않으면 성능이 가장 낮다.
- relative와 absolute position encoding을 사용하였을 때 relative가 성능이 가장 높다.
- attention이나 feature 분기에만 추가하면 성능이 낮아지기 때문에 두 branch에 모두 추가하는 것이 중요하다.

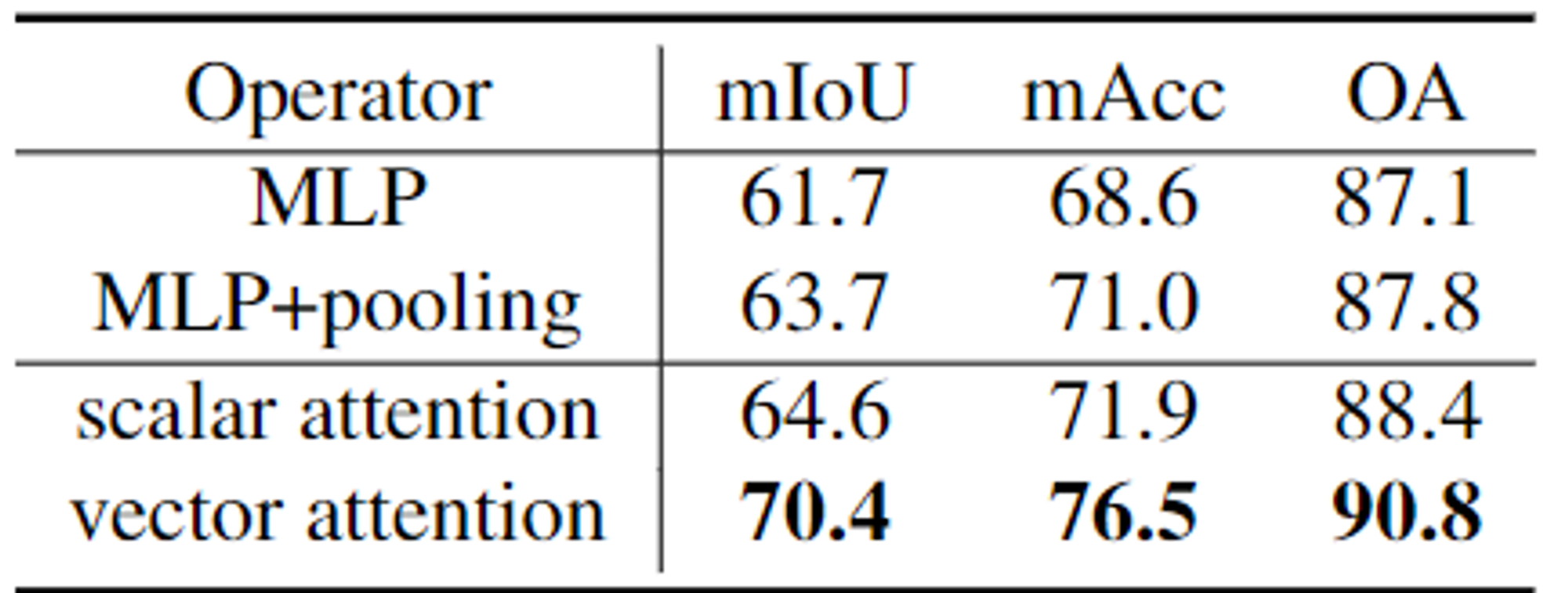
- Attention Type
- 기준이 없는 MLP layer, MLP layer 이후 knn 알고리즘을 기반으로 pooling, scalar attention, vector attention 네 가지 연산 중 vector attention이 가장 성능이 높다.
Conclusion
- 3D 데이터에 맞는 transformer 모델을 개발하였다.
- graph, convolution, sequence 처리 방식보다 더 좋은 네트워크 개발
- 다른 task에 적용가능
반응형